
Das DeepRain-Projekt ist eine Kooperation des Jülich Supercomputing Centre (JSC) am Forschungszentrum Jülich, des Deutschen Wetterdienstes (DWD), der Universitäten Osnabrück und Bonn sowie der Jacobs University in Bremen. Die Partner untersuchen, wie moderne Methoden des maschinellen Lernens eingesetzt werden können, um die Niederschlagsprognosen in Deutschland zu verbessern. Präzise Vorhersagen von Regen und Schnee mit einem zuverlässigen Hinweis auf die zu erwartende Niederschlagsmenge sind nach wie vor eine extreme Herausforderung für die Wettermodellierung, insbesondere auf den lokalen Skalen, wo sie am bedeutendsten sind.
Das Projekt nutzt Radardaten, hochauflösende topographische Daten und Ensemblevorhersagedaten aus einem numerischen Wettermodell und nutzt modernste Informationsverarbeitungstechnologie sowie erweiterte Statistiken für die Auswertung der neuen Prognosen. DeepRain wird vom Bundesministerium für Bildung und Forschung (BMBF) unter der Förderkennzeichen 01 IS 18047 gefördert und läuft vom 1. Oktober 2018 bis 30. September 2021.
Ziele
Ansatz
DeepRain geht in den vier Bereichen neue Wege: Datenfusion, Anwendung von KI, Validierungsmethoden und Big Data IT-Technologie.
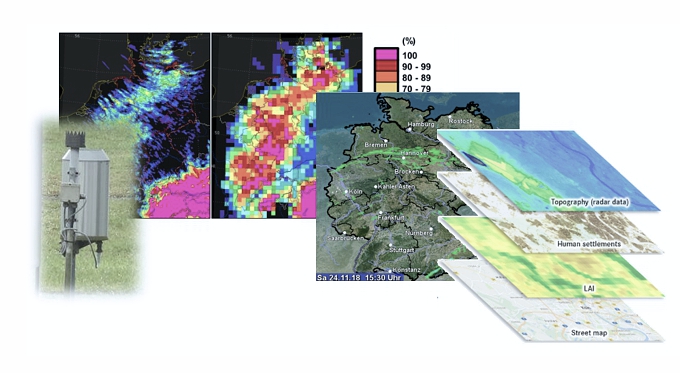
Fusion verschiedener Datentypen: Modell, Radar, Geographie, Zeitreihen, etc.
Ortsaufgelöste (Rasterpunkt-)Daten aus verschiedenen Datenquellen werden in die Array-Datenbank rasdaman importiert und stehen dort für eine flexible Hochleistungsextraktion zur Verfügung. Das Projekt wird zu erweiterten Abfragemöglichkeiten für die rasdaman-Datenbank führen.
Moderne Deep Learning-Technologien und neuronale Netzwerkarchitekturen werden an die spezifischen Anforderungen meteorologischer Datensätze angepasst. Im Gegensatz zu typischen Problemen der Bilderkennung oder Segmentierung steht DeepRain vor der Herausforderung, dass die Eingabedaten begrenzt sind (große Felder, aber geringe Anzahl von Proben). Komplexe und zeitaufwändige Modellfehler machen es zu einer Herausforderung, geeignete Datenstrukturen und neuronale Netzwerkarchitekturen auszuwählen. Außerdem folgen die Niederschläge bei weitem nicht einer Normalverteilung, und starke Regenfälle sind selten.
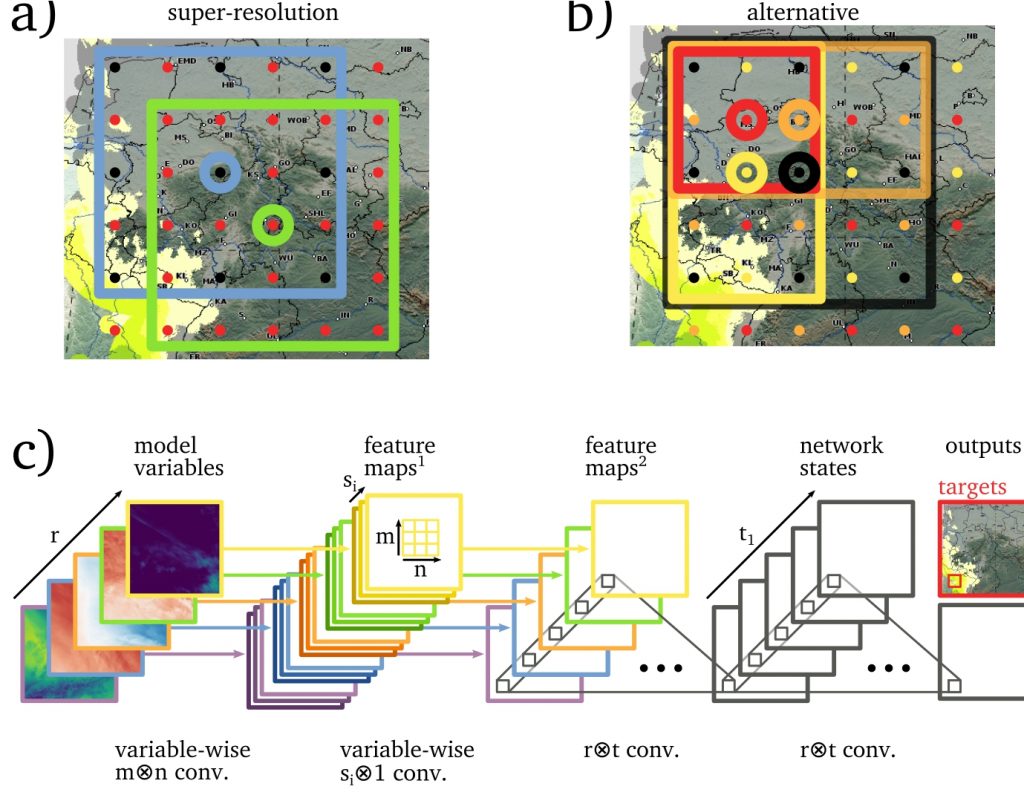
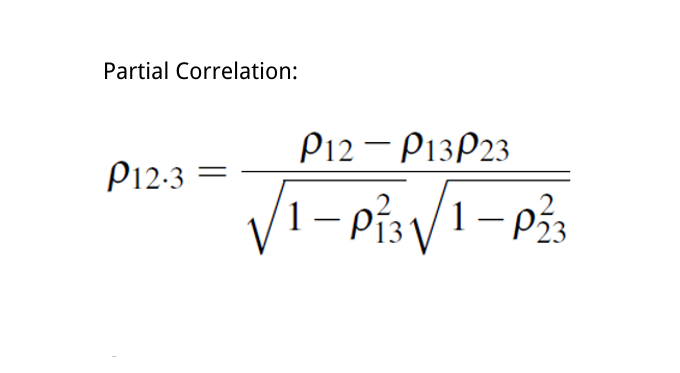
Fortgeschrittene statistische Techniken aus der Validierung und Nachbearbeitung von Klimamodellen werden an die Ergebnisse der Kurzstrecken-Wettervorhersage mit hoher Auflösung angepasst. Eine sorgfältige und robuste Auswertung der Deep Learning-Ergebnisse soll das Vertrauen in diese neuartige Technik stärken oder – wenn die Ergebnisse nicht überzeugend sind – kritische Benchmarks setzen, an denen zukünftige Versuche, klassische Downscaling-Methoden zu ersetzen, gemessen werden müssen.
Die Anzahl und Größe der meteorologischen Felder (insgesamt ca. 600 TBytes) und die Komplexität des Problems erfordern anspruchsvolle Daten und Arbeitsabläufe und bieten die Möglichkeit, neue Datenarchitekturen und Datenstaging-Konzepte auf den Jülicher Supercomputern JURECA und JUWELS zu testen. Das DeepRain-Projekt wird somit zu den Designentscheidungen zukünftiger exaskaliger Supercomputerarchitekturen beitragen.

Workflow
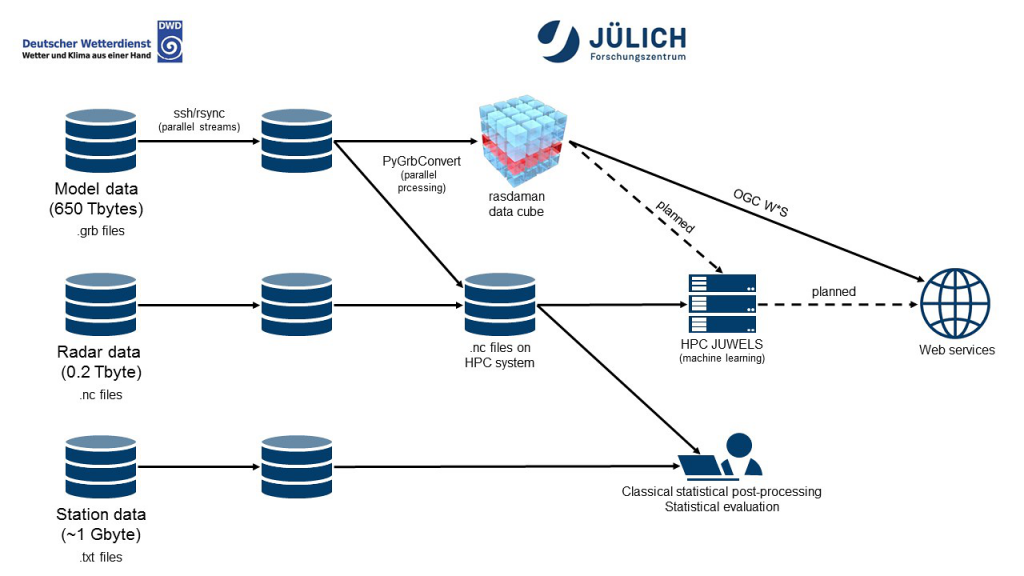
Die Grafik zeigt den Workflow, wie er bei DeepRain eingesetzt wird. Die verschiedenen Eingangsdaten werden zunächst in leistungsfähige Datenbanksysteme importiert und dort verarbeitet, so dass sie als Trainings-, Test- und Auswertungsdaten für das neuronale Netz zur Verfügung stehen. Die topographischen Daten sind statisch, alle anderen Datensätze enthalten zeitliche Veränderungen bis in die jüngste Vergangenheit. Vorhersagen sind auch aus dem Wettermodell verfügbar, das das neuronale Netz zum Herunterskalieren nutzen kann. Mit Hilfe des maschinellen Lernens wird zunächst für jeden Vorhersagezeitschritt eine räumliche Maske erzeugt, um die Punkte zu identifizieren, an denen Niederschläge wahrscheinlich auftreten werden, um sie weiter zu analysieren. Anschließend werden die Vorhersagen in drei Klassen für starke, mittlere und schwache Niederschläge unterteilt und für jeden Stützpunkt wird die Wahrscheinlichkeit für das Auftreten von Niederschlägen der jeweiligen Klassen berechnet, wobei die Kopplung zwischen benachbarten Gitterboxen berücksichtigt werden muss. Die Vorhersageergebnisse werden über eine Weboberfläche zur Verfügung gestellt, wo sie mit unabhängigen Daten von Stationsmessungen ausgewertet werden können.
DeepRain work packages
| WP1: Coordination and project management | |||
| WP2: Data processing and provision |  |
 |
|
| WP3: Method development for deep learning |  |
|
|
| WP4: Data consistency and classical downscaling algorithms | |
 |
|
| WP5: Evaluation and comparison of results | |
|
|
| WP6: System design and workflow analysis | |